Vision Language Models are In-Context Value Learners
† Work done while interning at Google DeepMind.
Accepted at ICLR 2025



GVL Zero-Shot results on OXE and 250 challenging bimanual tasks. Explore task completion predictions and frame-by-frame analysis across diverse robotic manipulation scenarios.
GVL auto-regressively predicts task completion percentage over shuffled frames, enabling impressive in-context value learning. GVL can effectively zero-shot and few-shot predict task progress on diverse and challenging real-world tasks; these capabilities enable expansive set of downstream applications, including dataset filtering, success detection, and policy learning.
Through extensive benchmark, we found our proposed framework can significantly enhance the ability of visual language models in performing different types of spatial reasoning like humans, as well as unlocking novel downstream applications such as robotics.
We introduce a lightweight, yet predictive method for evaluating value models at scale on real-world robotic datasets: Value-Order Correlation (VOC). This metric computes the rank correlation between the predicted values and the chronological order of the input expert video:
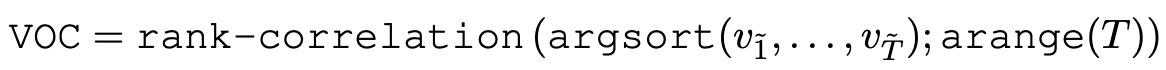
VOC ranges from −1 to 1, where 1 indicates that the two orderings are perfectly aligned. Expert quality demonstrations, by construction, have values that monotonically increase with time, and thus a good value model should have high VOC scores when evaluated on expert videos. On the other hand, fixing a good value model, low-quality trajectories should have low VOC scores. This is because sub-optimal trajectories often contain high repetition of visually similar frames due to the presence of redundant, re-attempt actions or poorly-placed cameras. As such, the values along the trajectories should not be monotonic, resulting in low correlation with the ground-truth timestep order.
GVL demonstrates appealing in-context scaling as the average VOC score steadily improves as we increase the number of in-context examples. Even with 5 in-context trajectories, meaning 150 total shuffled images, GVL is able to utilize its full context and exhibit strong generalization. This result demonstrates how state-of-art long-context-window VLMs, such as Gemini-1.5-Pro, can be re-purposed to make for general-purpose value functions with impressive test-time improvement capability, quickly mastering value predictions with minimal supervision.
Examples in-context are not limited to robot demon-strations. One advantage of GVL is that it can still benefit from in-context learning even when thedemonstrations come from a different embodiment. Specifically, we record humans performing thesame tasks as the ALOHA robot demonstrations and then use these human demonstrations as in-context examples for value prediction. As shown, GVL with one cross-embodiment in-contextexample can effectively improve over its zero-shot counterpart. In the Appendix, we also show thatGVL can similarly benefit fromcross-taskin-context learning. In conclusion, GVL presents a versatileframework for in-context value learning that can scale up to even the most challenging manipulation tasks.

We demonstrate that GVL's VOC scores can be used to estimate dataset quality. For each dataset in OXE, we compute the average VOC score for its sampled trajectories and present the ranking of the average scores. The full results are presented in paper Appendix. Here, we present a subset of selected representative large-scale datasets in OXE. We see that datasets have large spread in their VOC scores, but these scores are interpretable and match human intuitions. Specifically, datasets collected from human teleoperators with relative fixed camera placements, such as RT-1 (Brohan et al., 2022), Dobb-E (Shafiullah et al., 2023), and Bridge (Ebert et al., 2021; Walke et al., 2023), have high VOC scores, despite their diversity in scenes and tasks. In contrast, datasets with autonomous data collection via scripted motions or motor babbling, such as QT-OPT (Kalashnikov et al., 2018) and RoboNet (Dasari et al., 2019), contain high number of suboptimal trajectories that do not exhibit smooth temporal structure to be re-shuffled.
| Dataset | Avg. VOC |
|---|---|
| RT-1 (Brohan et al., 2022) | 0.74 |
| Dobb-E (Shafiullah et al., 2023) | 0.53 |
| Bridge (Walke et al., 2023) | 0.51 |
| QT-OPT (Kalashnikov et al., 2018) | 0.19 |
| DROID (Khazatsky et al., 2024) | -0.01 |
| RoboNet (Dasari et al., 2019) | -0.85 |
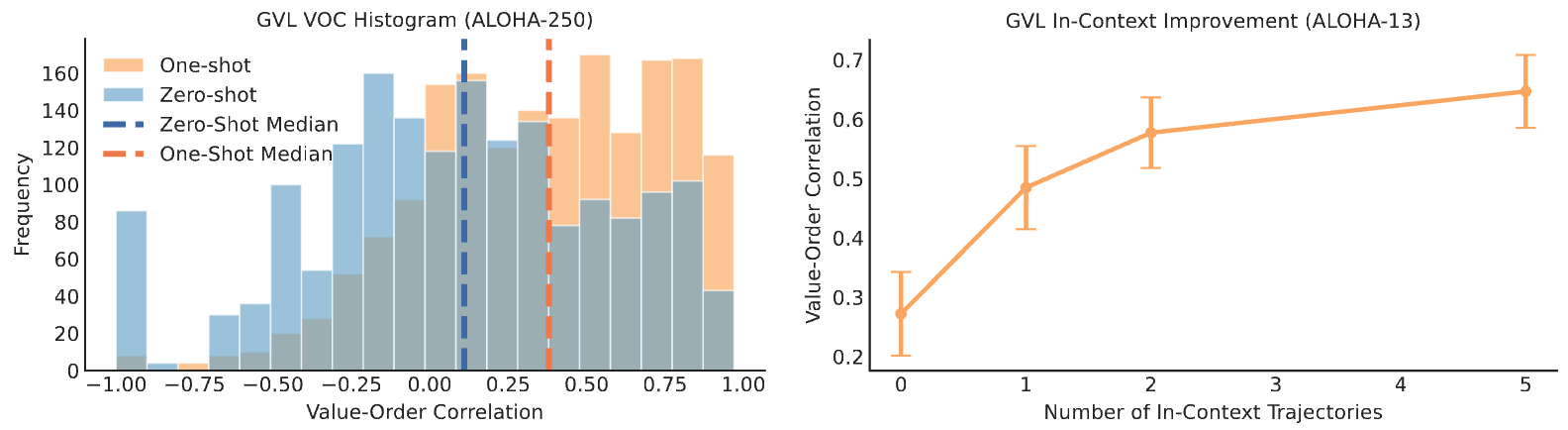
The VOC score can be used as a threshold score for success detection. The resulting success detection method, GVL-SD, substantially outperforms SuccessVQA using the same VLM on all evaluation metrics. Furthermore, filtered BC with GVL-SD always outperforms the base imitation learning algorithm (ACT) regardless of the threshold value.
| Method | Accuracy | Precision | Recall |
|---|---|---|---|
| GVL-SD (Zero-Shot) | 0.71 | 0.71 | 0.71 |
| GVL-SD (One-Shot) | 0.75 | 0.85 | 0.70 |
| SuccessVQA (Du et al., 2023) | 0.62 | 0.33 | 0.73 |
| SuccessVQA-CoT | 0.63 | 0.44 | 0.68 |
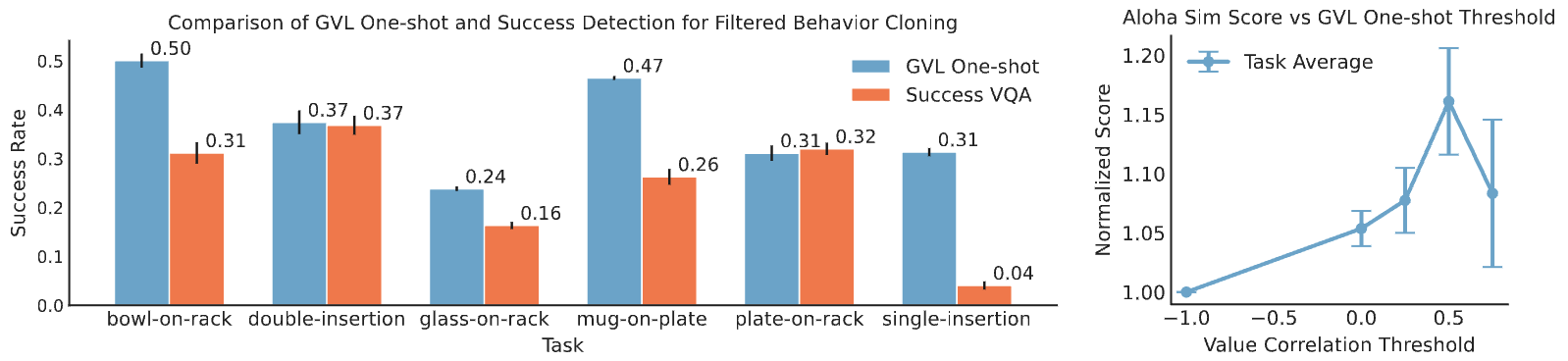
Qualitatively, we indeed see that GVL assigns much higher scores to successful trajectories than failure trajectories; in contrast, removing the shuffling mechanism in GVL significantly reduces its discriminability on failure trajectories.
We illustrate how GVL can assign importance weights to individual transitions within trajectories at a fine-grained level akin to offline reinforcement learning. For these experiments we use real-world demonstration data collected by human teleoperation on bi-manual ALOHA robot setups. Unlike simulation, our datasets only contain successful task executions but can be sub-optimal and multi-modal. Thus, we directly utilize GVL’s values with advantage weighted regression (AWR) (Peters & Schaal, 2007; Peng et al., 2019), in which we weight each individual transition by the estimated advantange, or GVL value difference for that step:
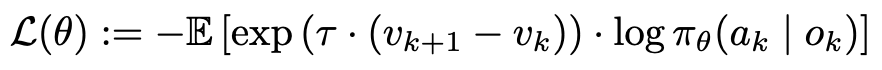
| Real-World ALOHA Tasks | GVL + DP | DP | Avg. VOC |
|---|---|---|---|
| bowl-in-rack | 7/10 | 6/10 | 0.57 |
| banana-handover | 7/10 | 5/10 | 0.73 |
| close-laptop | 9/10 | 6.5/10 | 0.59 |
| open-drawer | 4/10 | 6/10 | 0.09 |
| remove-gears | 4.67/10 | 7/10 | 0.19 |
| pen-handover | 1.5/10 | 0/10 | 0.43 |
| fold-dress | 7/10 | 7/10 | 0.66 |

We use diffusion policy (DP) as the policy backbone (Chi et al., 2023) for each task, and compare training diffusion policies with GVL (One-Shot) advantage weighting or lack thereof. We evaluate on 7 tasks with 10 trials per task and report success rate in Table 3. As can be seen, on a majority tasks, GVL-DP outperforms DP and we see a clear correlation between improvement over DP and the VOC score. That is, when the value predictions are of high quality as judged by VOC, policy learning can benefit from GVL value weighting. On open-drawer and remove-gears, the top-down view does not provide sufficient resolution to distinguish task progress (see Fig. 8), as a consequence, the value predictions can be noisy, which can hurt policy learning. However, given the in-context learning results, we believe that it is possible to improve policy learning even on difficult tasks with non-ideal camera viewpoints.
We show qualitative results on several robotic manipulation tasks below trained with Advantage-Weighted Regression. For each task, we show both successful and failed attempts.
Upload a video enter your Gemini API key and task description, then first shuffle it, and "Get Response" to analyze the frames.
After receiving the response, you can click "Parse Response" to see the predicted task completion percentage for each frame. You can toggle back to GT order to examine the predicted value function as well as the caption.
Or click one of the examples below to try:


We thank Jie Tan, Pannag Sanketi, Oliver Groth, and the rest the Google DeepMind Robotics team for helpful discussions and providing feedback on the paper.
@preprint{ma2024generative,
author = {Ma, Yecheng Jason and Hejna, Joey and Wahid, Ayzaan and Fu, Chuyuan and Shah, Dhruv and Liang, Jacky and Xu, Zhuo and Kirmani, Sean and Xu, Peng and Driess, Danny and Xiao, Ted and Tompson, Jonathan and Bastani, Osbert and Jayaraman, Dinesh and Yu, Wenhao and Zhang, Tingnan and Sadigh, Dorsa and Xia, Fei},
title = {Vision Language Models are In-Context Value Learners},
booktitle = {preprint},
year = {2024}
}